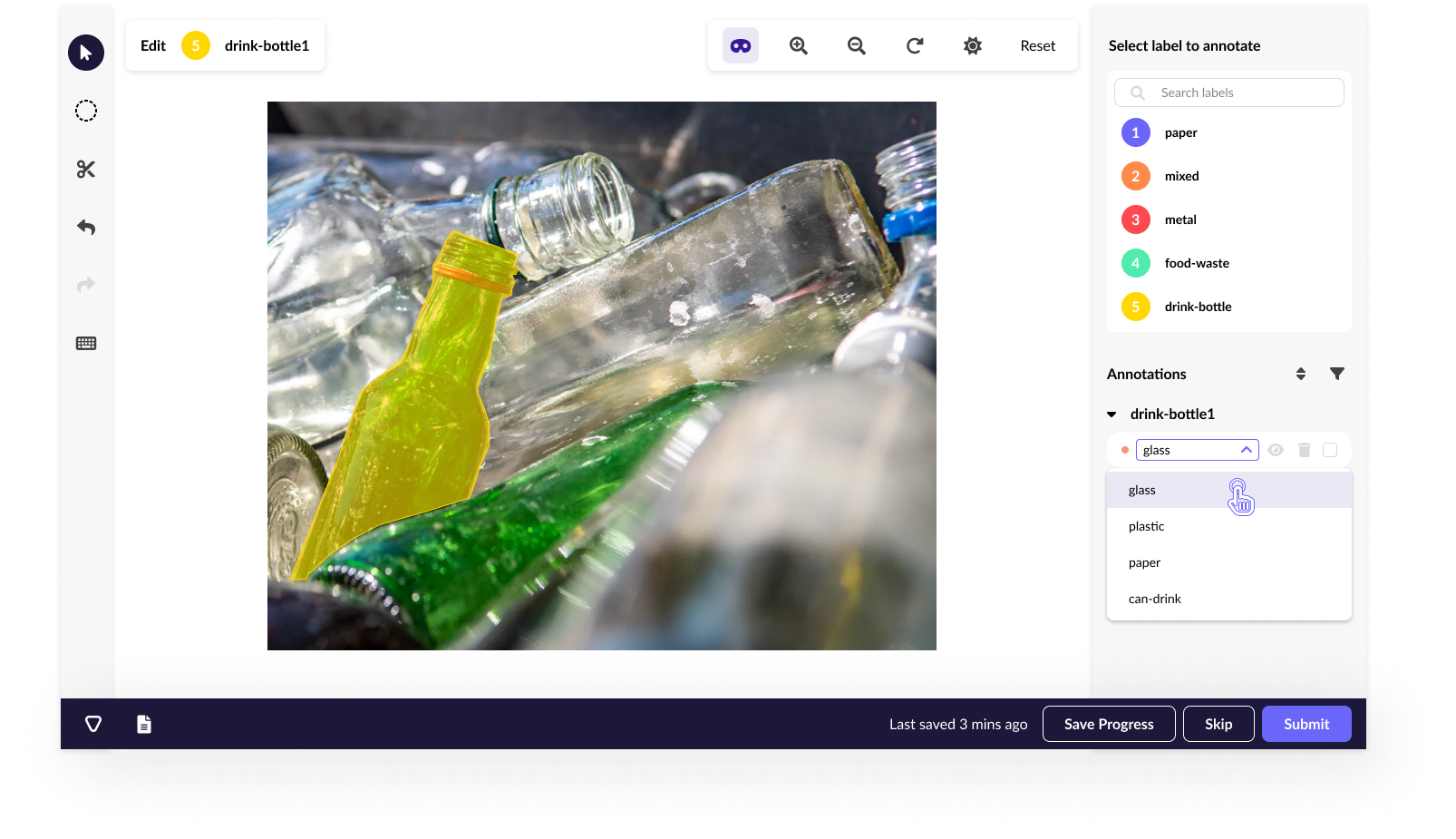
Data labeling—also known as data annotation—is an essential step in preparing datasets for machine learning (ML) and artificial intelligence (AI) models. By tagging or categorizing raw data (such as images, text, video, or audio) with specific labels, you provide your ML algorithm with the structured information needed to recognize patterns and make accurate predictions.
Without properly labeled data, ML models struggle to understand key features, leading to unreliable results. This guide explores what data labeling is, how it works, different approaches, best practices, and its real-world applications.
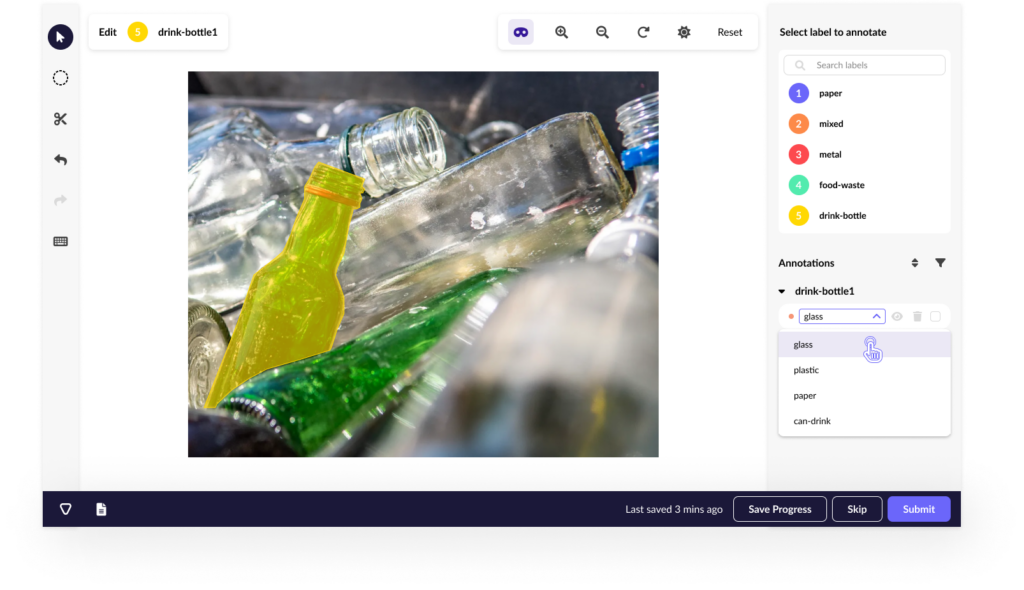
Table of Contents
- Introduction
- How Does Data Labeling Work?
- Labeled Data vs. Unlabeled Data
- Data Labeling Approaches
- Benefits and Challenges of Data Labeling
- Benefits
- Challenges
- Data Labeling Best Practices
- Data Labeling Use Cases
- Conclusion
- Further Resources
Introduction
In AI and ML, the quality of training data determines the effectiveness of a model. Data labeling is the process of assigning relevant tags to raw datasets, enabling algorithms to make sense of the information they process.
Data labeling plays a crucial role in:
- Supervised learning, where labeled data is required to train ML models.
- Improving data structure, ensuring datasets are ready for analysis.
- Enhancing AI applications, such as object detection, sentiment analysis, and speech recognition.
Well-labeled datasets lead to higher accuracy, better insights, and more effective AI models.
How Does Data Labeling Work?
Data labeling involves a combination of software tools, human expertise, and workflows to transform raw data into structured, machine-readable formats.
Steps in Data Labeling:
- Data Collection – Gather text, images, audio, video, or other raw data relevant to your AI model.
- Data Preparation – Remove duplicates, clean up inconsistencies, and standardize formats.
- Assign Labels – Add relevant annotations to each data point, such as bounding boxes, keywords, or sentiment scores.
- Quality Control – Verify the accuracy of labeled data through validation techniques.
Human-in-the-loop (HITL) review is often necessary to ensure high-quality labeling, especially in complex use cases where automation may struggle.
Labeled Data vs. Unlabeled Data
AI models rely on both labeled and unlabeled data. Understanding their differences helps determine the best ML approach.
- Labeled Data
- Used in supervised learning, where annotations guide the model in recognizing patterns.
- Typically requires manual intervention, making it time-consuming and expensive.
- Used in image recognition, speech analysis, NLP, and recommendation engines.
- Unlabeled Data
- Used in unsupervised learning, where models detect patterns without explicit labels.
- Easier and cheaper to obtain but requires advanced clustering algorithms to extract insights.
- Used in customer segmentation, fraud detection, and anomaly detection.
A hybrid semi-supervised learning approach combines both, reducing reliance on manual labeling while still guiding the model.
Data Labeling Approaches
Different labeling approaches balance cost, accuracy, and scalability. Here’s a look at the most common methods:
1. Internal Labeling
- Pros: Ensures high accuracy, allows direct oversight.
- Cons: Requires specialized talent and time-intensive efforts.
- Best for: Companies with large in-house data teams.
2. Synthetic Labeling
- Pros: Creates additional labeled data from pre-existing datasets, improving efficiency.
- Cons: Requires high computational resources.
- Best for: Augmenting datasets when real-world data is limited.
3. Programmatic Labeling
- Pros: Uses scripts and AI-based automation to accelerate labeling.
- Cons: Needs human verification for accuracy.
- Best for: Large-scale labeling tasks with predictable patterns.
4. Outsourcing
- Pros: Access to a specialized workforce without hiring internally.
- Cons: Requires robust quality assurance to maintain data integrity.
- Best for: Short-term projects with high labeling demands.
5. Crowdsourcing
- Pros: Cost-effective and fast, leveraging distributed workers for microtasks.
- Cons: Worker consistency can vary, requiring additional validation.
- Best for: Simple labeling tasks with high volume needs.
Benefits and Challenges of Data Labeling
Benefits
✅ Enhanced Model Accuracy – Well-labeled data ensures more reliable predictions.
✅ Better Data Usability – Structured datasets streamline analysis and AI applications.
✅ Scalability – Automated and programmatic approaches make it easier to scale AI models.
Challenges
❌ Resource-Intensive – High-quality labeling requires time, effort, and skilled workers.
❌ Human Errors – Inconsistent labeling can reduce model performance.
❌ Ongoing Maintenance – Labels may need to be updated as datasets evolve.
Data Labeling Best Practices
- Use Intuitive Labeling Tools – Streamlined interfaces reduce annotation errors and improve efficiency.
- Apply Consensus Methods – Have multiple labelers annotate the same data and resolve discrepancies.
- Implement Regular Audits – Periodic quality checks ensure data remains accurate and consistent.
- Leverage Active Learning – Prioritize labeling the most informative samples first.
- Adopt Transfer Learning – Utilize pre-trained models to reduce manual labeling efforts.
Data Labeling Use Cases
Data labeling supports AI development across industries:
📷 Computer Vision
- Object Detection – Bounding boxes around objects in images.
- Facial Recognition – Identifying faces for authentication.
- Medical Imaging – Analyzing X-rays and CT scans.
📝 Natural Language Processing (NLP)
- Sentiment Analysis – Determining emotions in text.
- Spam Detection – Filtering out irrelevant messages.
- Chatbot Training – Classifying user intents in conversations.
🎤 Speech Recognition
- Voice Commands – Enabling AI-powered assistants like Siri and Alexa.
- Transcription Services – Converting spoken language into text.
- Multilingual Processing – Identifying different languages in speech.
Conclusion
Data labeling is the backbone of effective AI and machine learning models. Whether for computer vision, NLP, or speech recognition, properly labeled data enhances accuracy and performance. While challenges like cost and time investment exist, adopting the right approach, tools, and best practices can optimize the process.
As AI adoption grows, the demand for high-quality labeled data will continue to rise, making data labeling a critical aspect of AI development.