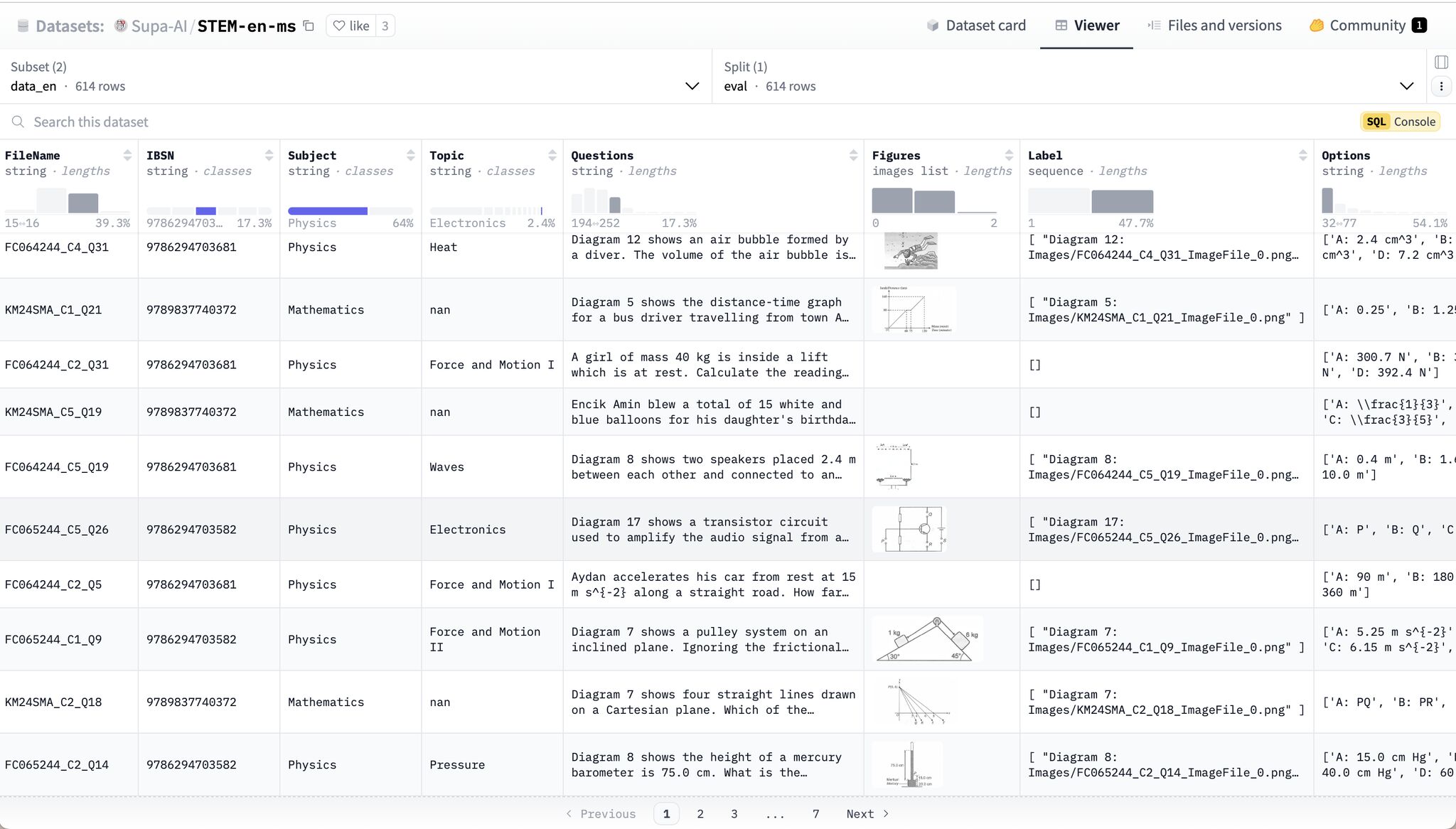
Fresh out of the oven! Our team just released a bilingual multimodal dataset for evaluating reasoning skills in STEM Subjects. This dataset features 500 high-quality MCQ questions from AP, SPM, and O-level Math and Physics.
👉 Explore it here: https://huggingface.co/datasets/Supa-AI/STEM-en-ms
Datasets Details:
Key Features
- Bilingual: Questions are available in English and Malay, promoting accessibility for multilingual learners.
- Visually Rich: Questions are accompanied by figures to enhance understanding and support visual and contextual reasoning.
- Focus on Reasoning: The dataset emphasizes questions requiring logical reasoning and problem-solving skills, as opposed to simple recall of knowledge.
- Real-World Context: Questions are derived from real-world scenarios, such as past SPM (Sijil Pelajaran Malaysia) examinations, making them relatable to students.
Dataset Structure
The dataset is comprised of two configurations: data_en (English) and data_ms (Malay). Both configurations share the same features and structure.
Data Fields
- Answers: Correct answer to the question, represented by the key of the correct option (e.g., “C”).
- FileName: Unique identifier for the source file (alphanumeric).
- IBSN: International Standard Book Number of the source book (if available).
- Subject: Academic subject (e.g., Physics, Mathematics).
- Topic: Specific topic of the question within the subject (may be missing).
- Questions: Main body of the question or problem statement.
- Figures: List of associated image files related to the question (empty if no figures are present).
- Label: Original caption or description of each image in the
imgslist. - Options: Possible answer choices for the question, with keys (e.g., “A”, “B”, “C”, “D”) and corresponding text.
- Answers: Correct answer to the question, represented by the key of the correct option (e.g., “C”).
Data Instance Example
{
"FileName": "FC064244",
"ISBN": "9786294703681",
"Subject": "Physics",
"Topic": "Measurement",
"Questions": "State the physical quantity that can be measured using the measuring device shown in Diagram 1.",
"Figures": [
{
"label": "Diagram 1",
"path": "FC064244_C1_Q12_ImageFile_0.png"
}
],
"Options": {
"A": "Weight",
"B": "Mass",
"C": "Amount of substance",
"D": "Volume"
},
"Answers": "B"
}
Data Split
The dataset is split between Physics and Mathematics subjects, with some questions lacking topic categorization.
| Subject | Instances with Topic | Instances without Topic | Total |
|---|---|---|---|
| Physics | 316 | 77 | 393 |
| Mathematics | 32 | 189 | 221 |
Known Limitations
- Subject Coverage: The current version focuses on Physics and Mathematics. Future releases will include more STEM subjects.
- Answer Accuracy: Answers are extracted from various sources and may contain inaccuracies.
Source
The dataset is derived from a combination of resources, including:
- SPM past-year exams
- SPM mock exams
- Educational exercise books
Data Acquisition Method
- Optical Character Recognition (OCR) for text extraction
- Manual quality control (QC) to ensure data accuracy
Versioning and Maintenance
- Current Version: 1.0.0
- Release Date: December 27, 2024
- Contact: We welcome any feedback or corrections to improve the dataset quality.
License
This dataset is licensed under the Creative Commons Attribution 4.0 International License (CC BY 4.0).
Getting Started
You can access the dataset on Hugging Face using the following commands:
# For English data
pip install datasets
from datasets import load_dataset
dataset = load_dataset("Supa-AI/STEM-en-ms", name="data_en")
# For Malay data
dataset = load_dataset("Supa-AI/STEM-en-ms", name="data_ms")
Bilingual STEM Dataset LLM Leaderboard
This document summarizes the evaluation results for various language models based on 5-shot and First Token Accuracy. The evaluation was conducted across four configurations:
| Model | en_withfigures | en_withoutfigures | ms_withfigures | ms_withoutfigures |
|---|---|---|---|---|
| gemini-2.0-flash-exp | 63.70% | 75.16% | 63.36% | 75.47% |
| gemini-1.5-flash | 49.66% | 67.39% | 50.00% | 64.28% |
| Qwen/Qwen2-VL-72B-Instruct | 58.22% | 69.25% | 57.53% | 63.66% |
| gpt-4o | 47.95% | 66.15% | 50.00% | 68.01% |
| gpt-4o-mini | 41.10% | 55.90% | 38.36% | 52.80% |
| pixtral-large-2411 | 42.81% | 64.29% | 35.27% | 60.87% |
| pixtral-12b-2409 | 24.66% | 48.45% | 24.66% | 39.13% |
| DeepSeek-V3 | None | 79.19% | None | 76.40% |
| Qwen2.5-72B-Instruct | None | 74.53% | None | 72.98% |
| Meta-Llama-3.3-70B-Instruct | None | 67.08% | None | 58.07% |
| Llama-3.2-90B-Vision-Instruct | None | 65.22% | None | 58.07% |
| sail/Sailor2-20B-Chat | None | 66.46% | None | 61.68% |
| mallam-small | None | 61.49% | None | 55.28% |
| mistral-large-latest | None | 60.56% | None | 53.42% |
| google/gemma-2-27b-it | None | 58.07% | None | 57.76% |
| SeaLLMs-v3-7B-Chat | None | 50.93% | None | 45.96% |
Notes on eval.py
eval.py is a template for evaluating large language models (LLMs), update the script to integrate your API calls or local model logic.
- The “First Token Accuracy” metric highlights initial token prediction accuracy.
- The evaluation results are based on the specific dataset and methodology employed.
- Further analysis might be needed to determine the models’ suitability for specific tasks.
Attribution for Evaluation Code
The eval.py script is based on work from the MMLU-Pro repository:
- Repository: TIGER-AI-Lab/MMLU-Pro
- License: Apache License 2.0 (included in the
NOTICEfile)